
Introduction
FoodVision Mini — an image classification project that recognizes food images as 🍕Pizza, 🥩Steak, or 🍣Sushi.
Instead of just experimenting in notebooks, I wanted to create something real:
- A modular deep learning pipeline
- A Gradio-powered interface
- A live deployment on Hugging Face Spaces
Whether you're just learning PyTorch or looking to deploy ML models, this blog walks you through the full-stack journey from training to deployment.
🔍 Project Overview
What does FoodVision Mini do?
Given an image, the model classifies it into one of three food categories using transfer learning with:
- EfficientNetB2 and
- Vision Transformer (ViT)
💡 I trained both models, evaluated their accuracy/speed, and deployed the better one for real-time use.
🏗️ Architecture
[Food101 Subset] --> [Transforms & Dataloaders] --> [EffNetB2/ViT] --> [Gradio Interface] --> [Hugging Face Deployment]
- Modularized with a src/ folder for reusable components
- CLI training scripts for reproducibility
- Clean separation of models, data, training, and UI
⚙️ Key Components
🧾 1. Dataset + Preprocessing
- Downloaded a small subset of the Food101 dataset (pizza, steak, sushi only)
- Applied resizing, normalization, and augmentation with torchvision.transforms
🧠 2. Model Training
I trained both:
- EfficientNetB2 using pretrained weights from torchvision
- ViT_B_16 for comparison on speed/accuracy
Each was trained via a dedicated CLI script:
1python scripts/train_effnetb2.py
2python scripts/train_vit.pyResults were saved and logged to .json files for visualization.
🧪 3. Evaluation
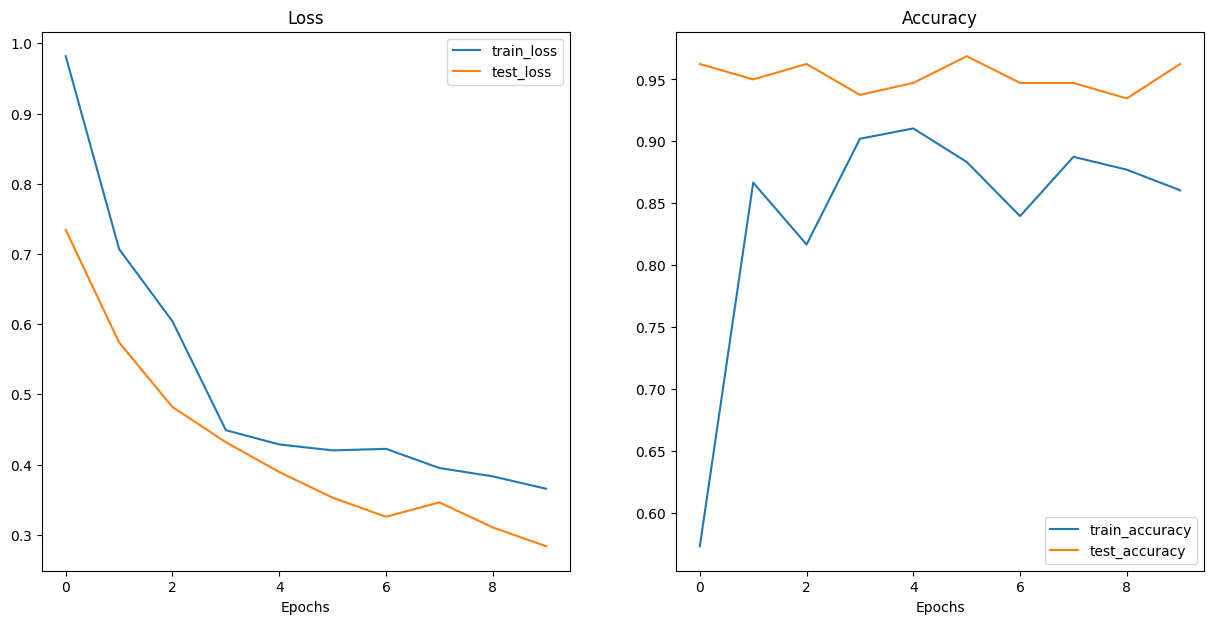
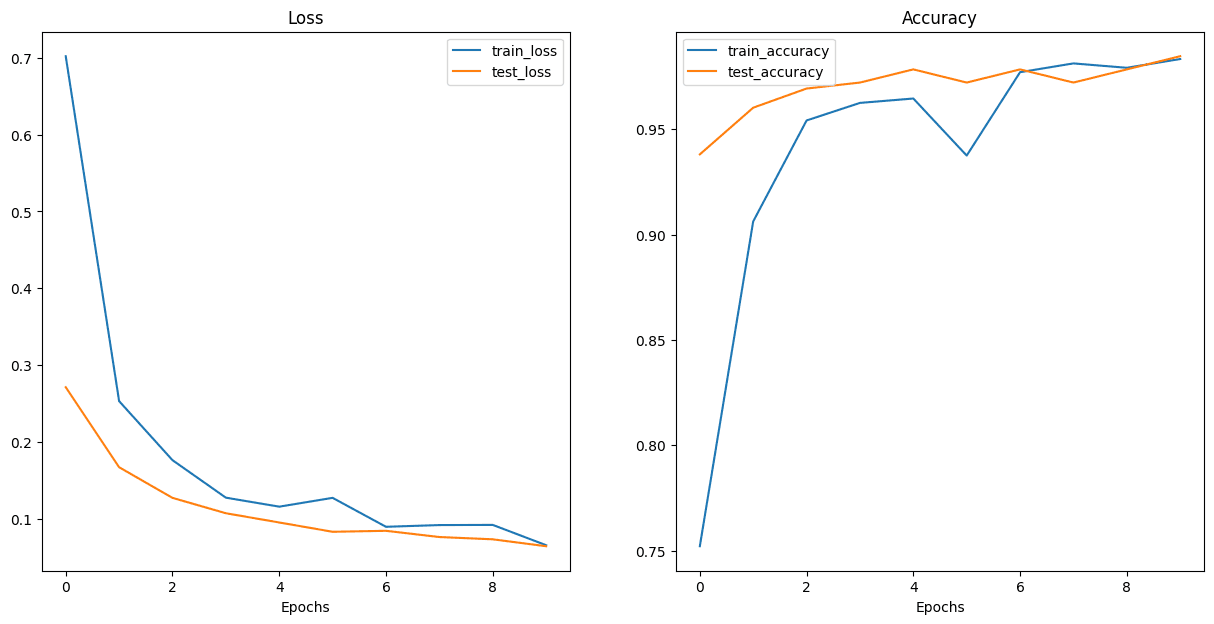
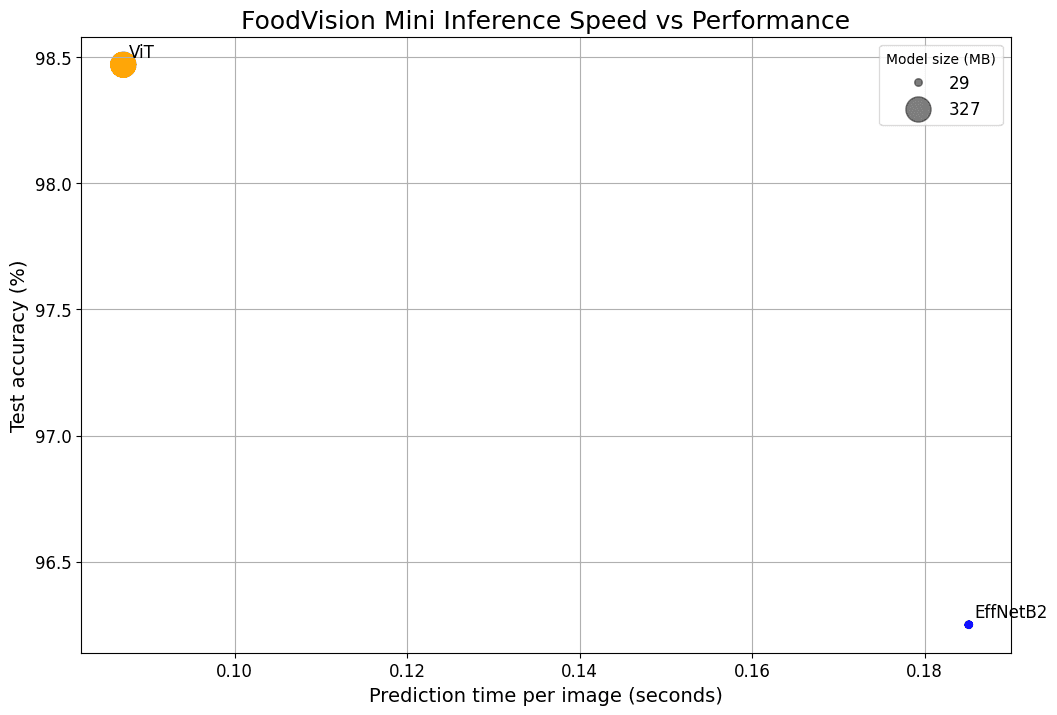
Plotted loss/accuracy curves and confusion matrices, and chose the better performing model based on:
- Inference time
- Validation accuracy
EffNetB2 Feature Extractor Loss/Accuracy Results
ViT Feature Extractor Loss/Accuracy Results
FoodVision Mini Inference: Speed VS Performance
🌐 4. Gradio UI
I built a modern Gradio interface:
- Upload or select example images
- Display top-3 predicted classes with confidence
- Prediction time visible for benchmarking
1demo = gr.Interface(
2 fn=lambda img: predict(img, model, transforms, CLASS_NAMES),
3 inputs=gr.Image(type="pil"),
4 outputs=[
5 gr.Label(num_top_classes=3, label="Predictions"),
6 gr.Number(label="Prediction time (s)"),
7 ],
8 examples=examples_list,
9 title=APP_TITLE,
10 description=APP_DESCRIPTION,
11 article=APP_ARTICLE,
12)🚀 5. Deployment on Hugging Face Spaces
- Used git-lfs to manage .jpg and .pth files
- Enabled a smooth preview on spaces
- Auto-regenerates examples via generate_examples.py
🔥 Live Demo
🎯 Try the model in action:
👉 Live on Hugging Face
💻 GitHub Repo
💡 What I Learned
This project helped me grow in:
- 🔍 Computer Vision: Learned how transforms and dataset management affect performance
- 🔄 Transfer Learning: Understood how freezing layers vs. finetuning affects model output
- ⚙️ Modular ML Code: Clean separation of training, prediction, deployment logic
- 🧪 Deployment Best Practices: From Git LFS to Gradio interface testing on Spaces
- 🚀 Developer UX: Thought about UI feedback, image loading, and prediction clarity
📦 Key Skills
- PyTorch, TorchVision
- EfficientNet, ViT
- Gradio Interface/Blocks UI
- Git LFS + Hugging Face Deployment
- Modular ML Architecture
✅ Final Thoughts
FoodVision Mini taught me that a project doesn’t have to be huge to be powerful — what matters is delivering a full loop: from training to real-time usage.
This project serves as a starter template for anyone trying to build real-world deep learning pipelines with:
- Fast iteration
- Clean interfaces
- Reproducible results
Want to build one yourself? Start with just 3 classes — and scale up to Food101.
📎 Resources
- 📦 GitHub: https://github.com/RahulSaini02/pytorch-foodvision-101
- 🤖 Live Demo: https://huggingface.co/spaces/sainir/foodvision-mini
- 📸 Dataset: torchvision.datasets.Food101